近日,微软旗下虚拟细胞项目组Project Ex Vivo在期刊《Nature Methods》上发表了一篇题为:“Evaluating the role of pretraining dataset size and diversity on single-cell foundation model performance”的论文。

论文在对400个单细胞基础模型开展了6400组实验评测后得出了一个颠覆行业认知的结论:
虚拟细胞似乎并不适用传统大语言模型“扩充数据-提升性能”的数据缩放规律,也就是说行业从100万卷到上亿的数据集规模大战,可能都走了弯路!
实验使用了一个包含2220万个细胞的大型数据集,结果显示仅使用当前海量训练数据中的一小部分(仅1%~10%),模型性能就会进入增长瓶颈。
单纯扩增数据规模、粗放增加数据多样性,都无法提升模型效果,部分复杂模型效果甚至不如传统简易算法,仅少量模型在数据小幅扩容时存在微弱提升。
也就是说,在AI虚拟细胞的研发中,一味扩大模型、数据与算力或许都是无用功,而细胞行为与状态的多样性才是模型训练核心!
虚拟细胞的下一程该怎么走?
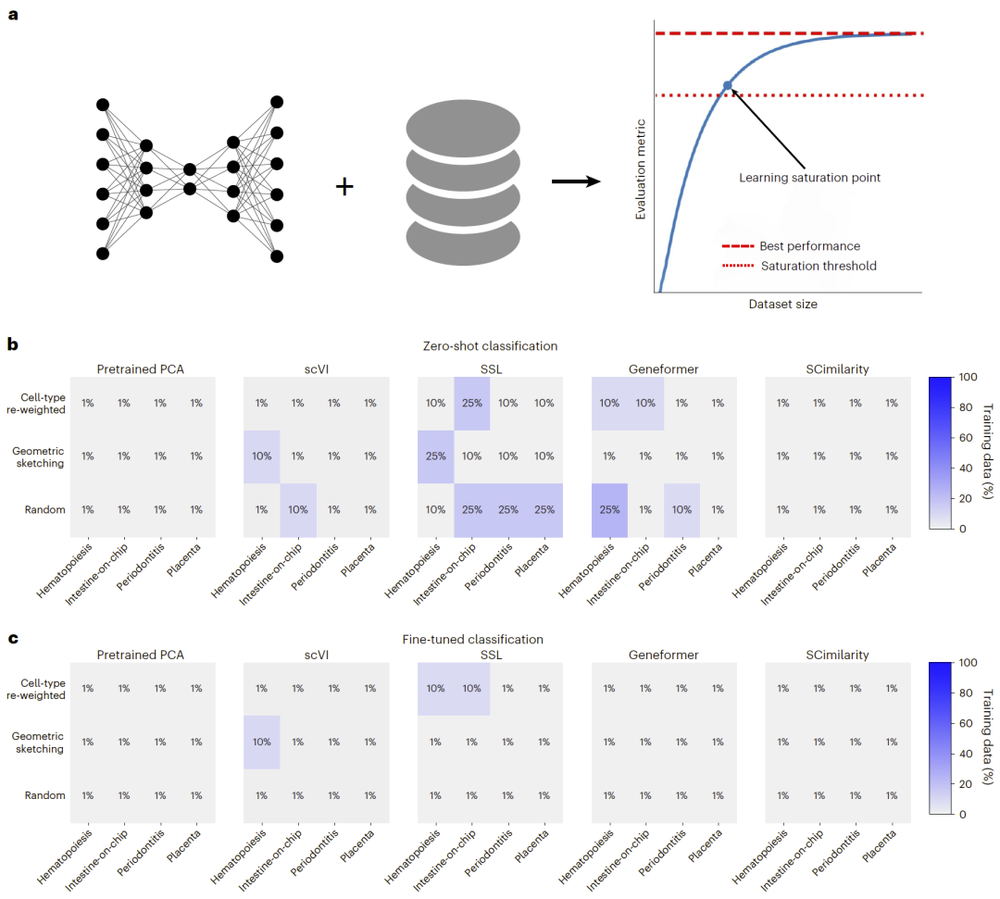
论文在最后写到,虚拟细胞或许需要精细化的研发思路:在平衡数据集规模与多样性的同时,兼顾模型架构、训练策略与评测体系的优化。
另外两位作者Peter S. Winter和Ava P. Amini分别补充到:“业内普遍认为只要不断扩大数据规模就能解决所有问题,但事实上,数据所涵盖的细胞状态多样性才是核心关键。”
“简单的嵌入方法(如PCA)往往被严重低估。在许多实际任务中,它们足以媲美甚至超越耗资巨大的Transformer模型。”
MIT+哈佛 用虚拟细胞攻克癌症难题
本研究隶属于微软旗下的虚拟细胞项目组Project Ex Vivo,由该公司与麻省理工和哈佛共建的博德研究所(Broad Institute)联合开展,并得到全美最大癌症研究中心丹娜-法伯癌症研究所(DFCI)的支持。
项目建立于2022年,旨在将细胞状态纳入癌症分型与治疗体系,实现药物与患者的精准匹配,改善癌症患者预后。
团队利用计算模型开展虚拟细胞实验,先通过运算验证科研假设,再进行实体实验,还通过AI预测药物引发的细胞状态变化,以及不同癌种中细胞状态的演变规律。
团队认为,实验室培育的癌细胞以及类器官这样的微型肿瘤模型,无法完全复刻人体内肿瘤的真实状态,这是导致许多在培养皿中表现亮眼的候选药物,最终在临床试验中折戟的关键因素。
他们把研究重心放在细胞状态上,这直接决定肿瘤的药物敏感度、耐药性产生速度以及恶性侵袭能力,一方面有利于现有疗法的患者匹配方案,另一方面也能为药物研发开辟新方向。
研究人员不再局限于靶向基因突变,还可研发针对细胞状态的疗法,甚至通过调控细胞状态,让恶性肿瘤转变为更易治疗的类型。
推荐阅读