AI将如何重塑生物技术的未来?
英伟达给出了自己的答案。
“AI界春晚”英伟达GTC大会开幕当天,英伟达发布了一款蛋白质模型Protein-Complexa。
团队表示,这是当前最先进的蛋白质开源基础模型,它一步就能生成蛋白质的序列和原子级结构,开箱即用!
研发团队做了史上最大规模的湿试验验证。
针对127 靶点中,86个达到命中,91.2%为靶点特异性。
单个蛋白质下,命中率高达63.5%, 且有皮摩尔级亲和力,有望直接成药!
甚至,Protein-Complexa首次从头设计出能结合碳水化合物的蛋白质,传统方法下这根本做不到!
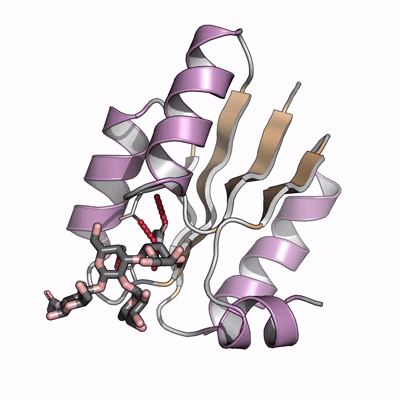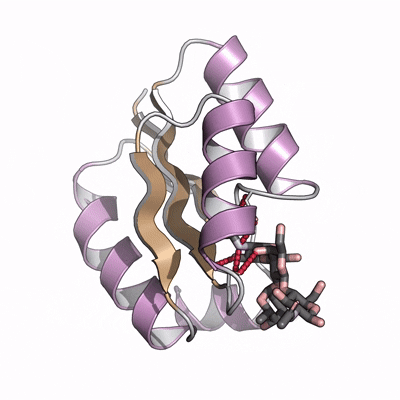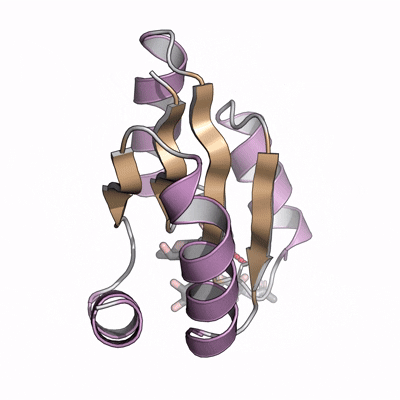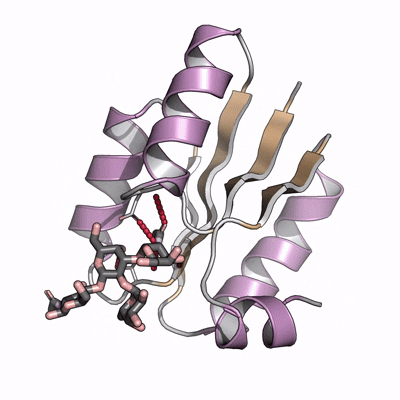
图:碳水化合物的结合剂设计
据悉,医药巨头诺和诺德已经利用该方法进行药物研发,并进行实验验证。
团队已经将该项目开源。
开源地址:
https://github.com/NVIDIA-Digital-Bio/Proteina-Complexa
不止如此,对生命健康抱有极大野心的英伟达,还宣布了一系列合作和产品。
包括英伟达和罗氏开启了一项重磅合作,发布面向医药的高性能仿真工具、扩充AphaFold数据库等。
毫无疑问,英伟达的一系列动作的终极目的,是用AI改变整个生命健康的格局。
一步生成蛋白质
当前,蛋白质从头设计技术进展迅速,主要分为两大主流技术路径。
要么根据蛋白质模板信息,实际用的时候直接生成设计结果,不会再优化调整;
要么就是按照hallucination的方式,模型不依赖提前训练的生成规则,而是在实际设计时,从零开始生成优化结合剂序列/结构。
这两种方法都有短板,还得搭配额外模型,进行序列设计与优化。
与之相比,Protein-Complexa是首个在连续潜在空间中进行序列-结构联合生成+推理时搜索的蛋白质设计方法。
这种方法统一了生成与优化,克服了传统方法(如RFdiffusion、BindCraft)依赖独立逆折叠模型的局限性。
这种方法结合了两种方法的长处。
既能同时设计蛋白质的序列和结构,且无需逆折叠,在实际使用模型时做针对性优化。
因此生成序列是直接使用的,无需单独的重新设计步骤。
这种全新方式直接扩展蛋白质设计的能力边界。
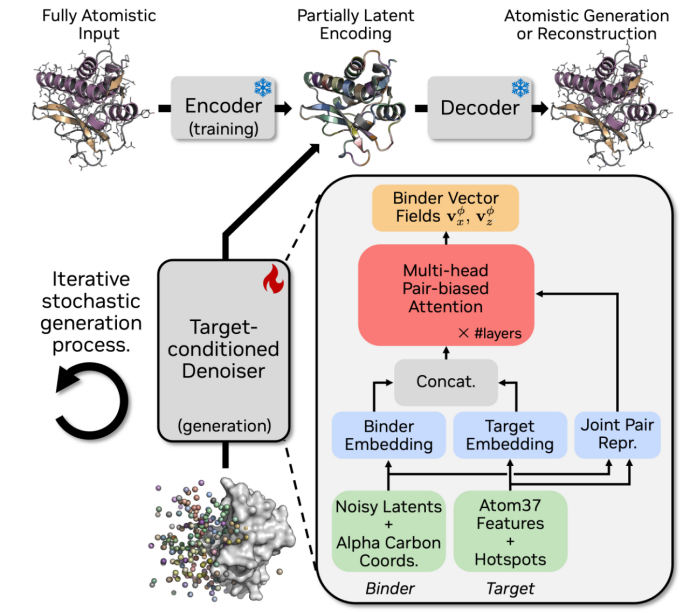
Protein-Complexa的模型结构
为了解决实验数据稀缺的问题,团队还构建了名为
Teddymer的 结合剂—靶点配对数据
该方法还大大节省了算力成本。
由于它能端到端同步生成序列和结构,省去了传统方法中先设计再用其他模型反向折叠/优化的步骤,避免了额外的算力消耗。
在虚拟实验的基准测试中,Proteina-Complexa 生成单个结合剂样本的耗时远低于 RFDiffusion、APM 等主流方法。
如蛋白质靶点设计中,Proteina-Complexa耗时15.6秒,远低于 RFDiffusion 的 70.8 秒,相同算力下能生成更多候选样本,进一步提升筛选到优质结合剂的概率。
迄今最大规模的实验性头对头比较
为了验证模型效果,英伟达联合多家生物公司、高校做了超大规模实验,生成了超100万种设计的结合剂。
结果显示,Proteina-Complexa 是目前从头设计蛋白质结合剂最强的开源模型。
首先,模型的广谱性强。
团队测试了127个不同类型的靶点里,成功设计出能和其中86个靶点结合的蛋白质。这样的适用广度,远超市面上主流蛋白质生成模型。
图:Proteina-Complexa结果涵盖127个靶标
其次,Proteina-Complexa和市场上领先的模型进行比较评估,BoltzGen、RFDiffusion3、BindCraft,多个任务中都实现了超越。
团队将Proteina-Complexa和BoltzGen、RFDiffusion3、BindCraft等多个蛋白质生成模型进行比较,在75个靶点上评估了每个方法的序列重新设计组合的设计命中率及特异性。
结果显示,Proteina-Complexa在所有靶点的平均命中率为2.45%。
这个数字看起来不高,但要知道,第二名BoltzGen的成功率只有0.76%,相当于Proteina-Complexa的3倍多。
就算是最好的“二次优化型”方法(BoltzGen+ProteinMPNN),成功率也只有1.81%,Proteina-Complexa比它也高出了近1.5倍。
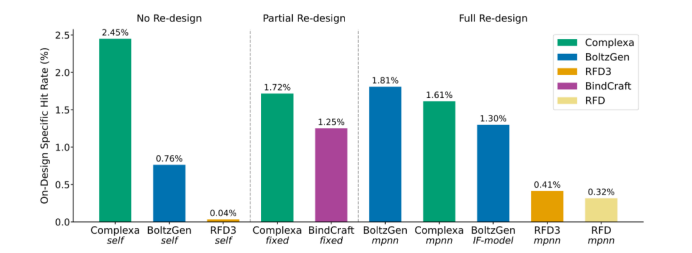
不止如此,Proteina-Complexa还有一个极大的优势——高特异性。
它设计出的结合剂,91.2%都能精准结合靶点,不会结合其他蛋白质。
这一点在药物设计中至关重要,要是结合剂与其他受体进行结合,不仅达不到治疗效果,还可能对身体造成伤害。
除了大规模靶点筛选外,团队还在单个靶点上测试了Proteina-Complexa,并对候选分子进行了更为细致的筛选和筛选。
例如,针对 PDGFR(血小板衍生生长因子受体)这样有挑战性的受体,命中率高达63.5%,最强的结合剂亲和力达到皮摩尔级别。
对小分子靶点和酶设计任务的扩展,再次超越了以往方法,比如Proteina-Complexa针对激酶微蛋白和肽结合剂的命中率为40%-50%。
甚至该方法还首次设计出了能够结合碳水化合物的分子,填补了该领域的设计空白。
要知道碳水化合物体积小,极性密集,表面富含羟基,没有疏水性。此前没有计算方法设计出能结合游离碳水化合物的蛋白质。
然而,团队针对血型B抗原为设计靶点,这是一种对ABO移植兼容性至关重要的三糖。
团队生成了24个设计候选,基本都能在大肠杆菌中成功表达,意味着设计具有落地性。
其中,5个能实现B型血红细胞凝集,凝集信号达到阳性对照的2.6~3.6倍,单次设计就实现了21%的命中率。
其中最优候选NV15经实验验证,可直接与碳水化合物发生浓度依赖性的特异性结合,且通过圆二色谱验证,其热稳定性超过95℃,具备极强的环境适应性,为后续实际应用奠定了坚实基础。
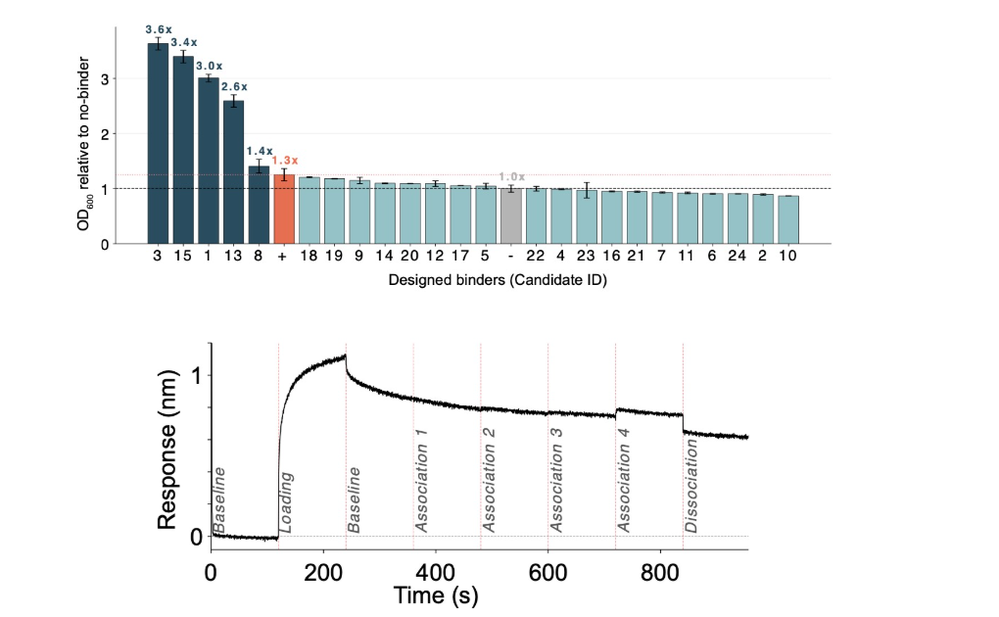
图:针对B型血型碳水化合物生成的结合剂
综合所有这些数据来看,团队表示,Proteina-Complexa已经毫无疑问地成为了目前最先进、最靠谱的开源蛋白质设计模型。
该模型已经吸引了生物医药企业的关注。
诺和诺德、维亚生物和Manifold Bio正在用其设计能够结合靶标蛋白的蛋白质,并对生成的设计进行了实验测试。
英伟达GTC,还有哪些进展?
除开Proteina-Complexa外,英伟达在GTC还宣布了很多夯货。
与罗氏重磅合作
罗氏与英伟达宣布扩大现有合作,将人工智能和加速计算转变为其制药和诊断业务的核心运营能力。具体而言,双方将在美国和欧洲的混合云和本地环境中部署超过3500个英伟达Blackwell GPU,这也是迄今为止制药公司公布的最大GPU部署规模。
扩展AlphaFold数据库
英伟达联合Google DeepMind等机构,为AlphaFold蛋白质结构数据库新增了约3100万条蛋白质复合物预测,其中180万条为高置信度预测,加速新药靶点发现。
推出面向医药的高性能仿真工具nvQSP
这是一款定量系统药理学仿真引擎。在基准测试中,其速度比传统CPU快77倍,能让研究人员在临床试验前更高效地模拟不同剂量和患者群体的反应。
发布医疗机器人AI平台
推出了首个面向医疗机器人的物理AI平台,包含全球最大的手术视频数据集Open-H(含776小时视频)和预训练模型,旨在推动手术机器人的自主化研究。
包括全球最大的医疗机器人数据集 Open-H、Cosmos-H 开放模型家族、GR00T-H VLA 模型、Rheo 开发蓝图。
简而言之,英伟达正在围绕医疗健康构建一个从底层算力、基础模型到行业应用的完整AI生态。
推荐阅读