

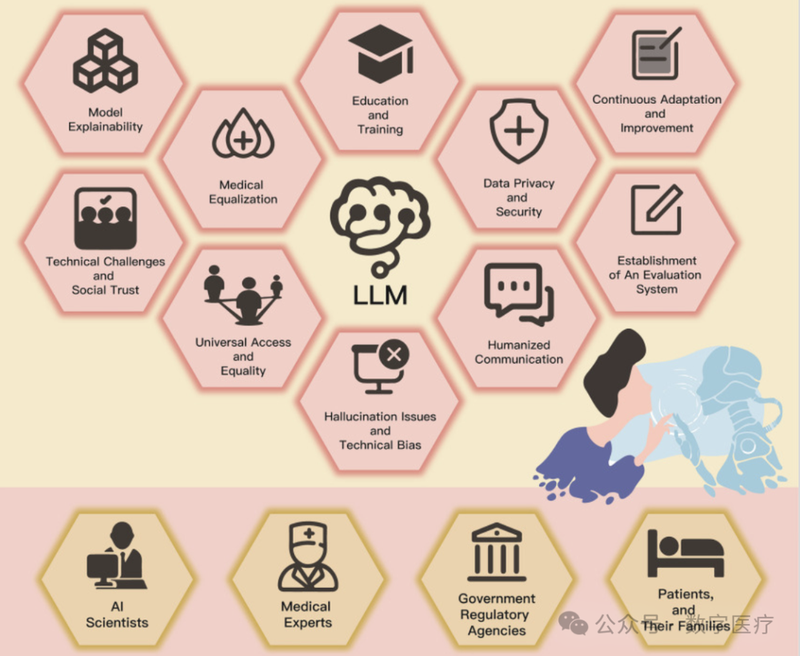
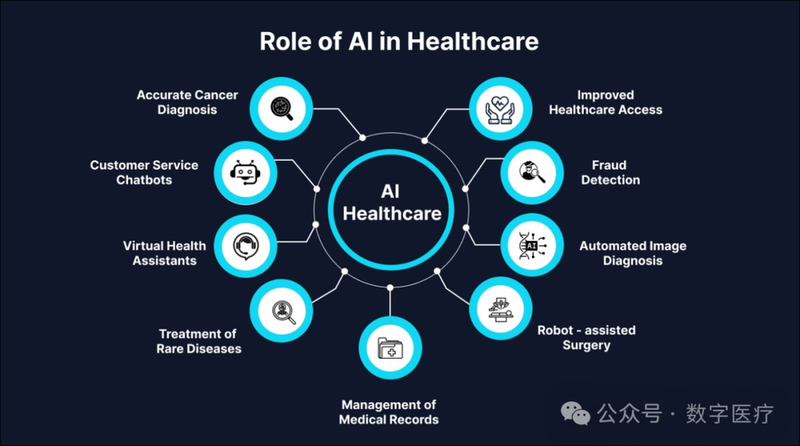





Too many people think that the grass is greener somewhere else but the grass is green where you water it. Remember that. 世人总以为别处的草色更绿,殊不知,何处用心浇灌,何处便有青青芳草。请铭记于心!早上好!

Too many people think that the grass is greener somewhere else but the grass is green where you water it. Remember that. 世人总以为别处的草色更绿,殊不知,何处用心浇灌,何处便有青青芳草。请铭记于心!早上好!