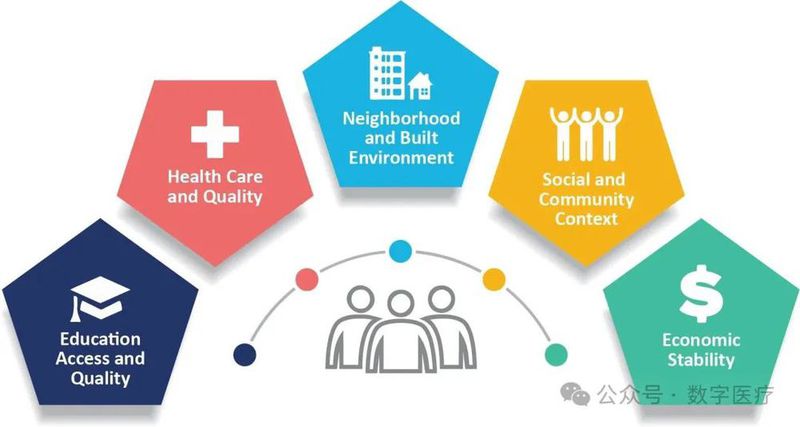
本文探讨了如何结合大语言模型与传统深度学习方法,自动从临床文本中提取“健康的社会决定因素”(SDoH),并预测其对患者健康的影响。SDoH是指影响个体健康状况的经济、社会和个人环境因素,如安全住房、就业机会、歧视和环境因素等。准确识别和预测SDoH对于医生诊断疾病和制定治疗方案具有重要意义。
研究背景与动机
传统的电子病历虽然包含了SDoH的结构化数据,但许多系统并未全面记录这些信息,或者数据格式差异很大。为了解决这些问题,研究人员开始利用自然语言处理技术从临床文本中自动提取SDoH。当前,基于大语言模型的自然语言处理方法在SDoH提取中表现出色,但存在计算成本高、处理速度慢等缺点。因此,研究如何结合大语言模型与传统深度学习,以兼顾精度和效率,成为了一个重要的研究方向。
数据集与方法
●数据集
本研究使用了两个主要数据集:一是来自MIMIC-III的子集,包含5355条临床笔记句子,标注了零个或多个SDoH标签;二是基于大语言模型生成的合成数据集,包含588条标注了至少一个SDoH的句子。这两个数据集为模型训练和测试提供了丰富的数据支持。
●方法概述
本研究采用了多种模型进行SDoH分类,包括Llama系列的大语言模型和传统深度学习模型(如RoBERTa Base)。实验设置了少样本学习和监督微调两种模式,并比较了不同模型在多标签和二分类任务中的表现。此外,研究还提出了一种两步分类法,结合了传统深度学习模型的效率和大语言模型的精度。

实验结果与分析
●模型性能
实验结果表明,经过微调的Llama3.1 8B Instruct模型在MIMIC-III数据集上的多标签分类任务中表现最佳,宏观F1值达到0.67。然而,传统深度学习模型RoBERTa Base在加权平均F1值上表现更优,达到了0.97。在合成数据集上,所有模型的表现均有所提升,表明合成数据对模型训练具有积极作用。
●两步分类法
两步分类法结合了传统深度学习模型的快速预测能力和大语言模型的高精度分类能力。实验结果显示,该方法在保持较高分类精度的同时,显著提高了分类速度。具体来说,两步分类法首先使用传统深度学习模型判断句子中是否包含SDoH,若包含则使用大语言模型进行多标签分类。
●特征组合与模型优化
本研究还探讨了不同特征组合对模型性能的影响。通过与传统深度学习模型的结合,发现词性标签、依赖关系树深度和命名实体等特征在SDoH提取中非常有用。此外,本研究还发现,虽然合成数据有助于提升模型性能,但直接使用大语言模型生成的标签可能存在噪声,影响模型精度。

讨论与启示
●精度与效率的平衡
本研究展示了如何通过结合大语言模型与传统深度学习模型,在SDoH预测任务中实现精度与效率的平衡。传统深度学习模型在处理大规模数据时具有显著的速度优势,而大语言模型则能在需要高精度的场景下发挥作用。两步分类法的提出,为解决这类问题提供了新的思路。
●合成数据的应用
合成数据在模型训练中表现出了积极作用,尤其是在数据稀缺的情况下。然而,如何有效利用合成数据,避免噪声对模型性能的影响,仍需进一步研究。未来的工作可以考虑开发更先进的合成数据生成方法,以提高数据质量和模型泛化能力。
●临床应用的潜力
本文提出的模型和方法在SDoH预测中表现出了较高的性能和效率,为临床应用提供了有力支持。未来,随着技术的不断进步和数据资源的日益丰富,这些方法有望在电子病历系统、远程医疗和个性化医疗等领域发挥更大作用。
结论
本文通过结合大型语言模型与传统深度学习方法,在SDoH预测任务中取得了显著成果。提出的两步分类法有效平衡了分类精度与处理速度,为解决类似问题提供了新的思路。未来的研究可以进一步探索合成数据的应用、模型优化和临床应用潜力,以推动该领域的技术进步和实践发展。
如需要《大语言模型与传统深度学习在健康的社会决定因素预测中的融合》(英文,13页),请在本微信公众号中赞赏(点喜欢或稀罕作者后按本公众号设定打赏)后,发来email地址索取。



You learn a lot about people when they don't get what they want from you. 当人们未能从你处得偿所愿时,你便能洞悉其人性百态。早上好!
