近年来,随着大语言模型(LLMs)的发展,Scaling Law 成为AI研究的重要风向,推动模型参数量不断攀升至百亿甚至千亿级别。然而,这种趋势也带来了高昂的计算成本,使得许多小型研究团队难以负担。
近日,阿里云团队GenerTeam在预印本平台bioRxiv上发布了题为Generanno: A Genomic Foundation Model for Metagenomic Annotation的最新成果,开发出DNA大模型GENERanno。
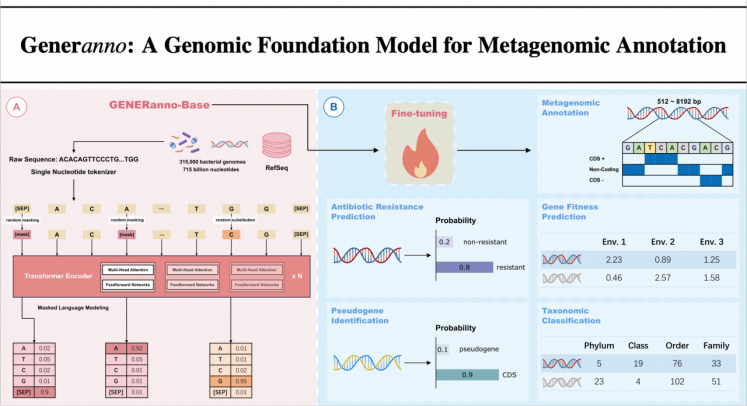
传统的基因注释工具在处理复杂环境(如土壤、污水、人类肠道等)中的宏基因组样本时,往往显得捉襟见肘。这些样本通常混合了来自大量不同物种的DNA碎片,传统方法难以高效解析其中的功能信息。而GENERanno 的诞生,为这一领域提供了新的解决方案。
作为一款专为宏基因组分析设计的紧凑型基因组基础模型(Genomic Foundation Model, GFM),GENERanno仅有5亿参数,但却在测试中展现出了超强性能,在多项任务中超越了参数量高达40亿的 GenomeOcean-4B。
这一结果验证了一条不同于Scaling Law的道路——通过小巧而高效的设计,使模型在性能与计算成本之间实现了平衡,证明了“小而美”的模型在科学领域的巨大潜力。
什么是GENERanno?
GENERanno基于 Transformer Encoder 架构打造,训练数据涵盖了7150亿碱基对(bp)的原核DNA。作为一款专为宏基因组分析设计的紧凑型基因组基础模型(Genomic Foundation Model, GFM),GENERanno 仅有5亿参数,能够以单核苷酸分辨率处理长达8192bp的DNA序列。
GENERanno的核心优势
1、宏基因组注释
宏基因组注释是指从复杂的宏基因组DNA片段中准确预测编码区域(CDS regions)。在广泛的原核物种测试中,GENERanno 展现了卓越的性能。
与传统HMM方法(如GLIMMER3、GeneMarkS2和Prodigal)以及近期发布的基于GFM的基因注释工具GeneLM相比,GENERanno不仅能够更精准地识别基因边界,还在碱基对级别的注释精度和灵敏度上实现了显著提升。
得益于其紧凑高效的模型架构,GENERanno 在注释效率方面同样表现出色:使用单卡4090,仅需1分钟即可完成长达460万 bp 的大肠杆菌基因组注释,用时几乎与传统HMM方法相当。
2、卓越的泛化能力
泛化能力是衡量模型面对未知数据表现的重要指标。为了验证GENERanno 的跨物种迁移能力,研究团队在模型从未见过的古菌(archaea)序列上进行了“样本外”测试。
结果显示,GENERanno 大幅领先于GeneLM,其性能几乎超越了传统HMM方法在“样本内”测试中的水平。这种卓越的泛化能力意味着,即使面对尚未被充分研究的新细菌或古菌基因组,GENERanno 依然能够提供高度可靠的注释结果,为探索未知微生物群落提供了强有力的支持。
3、伪基因预测
伪基因是一类失去功能的非编码序列,通常由功能性基因经过突变或基因组重排后形成。由于伪基因与功能性基因在序列上高度相似,传统方法往往需要依赖比较基因组学和功能性实验来区分二者,不仅耗时耗力,还需要庞大的参考数据库支持。
GENERanno利用其强大的上下文理解能力,能够直接从原始序列中区分伪基因与活性编码区域,极大地简化了伪基因预测流程。这种高效的解决方案不仅提升了注释效率,还为研究基因组进化和功能丧失机制提供了新的视角。
4、分类学注释
分类学注释是宏基因组学的核心任务之一。传统方法通常依赖特定标记基因(如16S rRNA)进行物种分类,但这种方法需要先将碎片化的DNA序列组装成连续的contigs,再从中识别标记基因,整个过程计算资源消耗巨大且容易出错。
GENERanno提出了全新的解决方案,它能够直接从随机 DNA 片段中完成物种分类,无需依赖标记基因或组装步骤。这种创新方法显著提高了分类效率,使得复杂样本(如污水或土壤中的混合微生物群落)的快速分析成为可能,为宏基因组学研究开辟了新途径。
Prokaryotic Gener Tasks:开创性的基准测试
为了全面评估GENERanno 及其他基因组基础模型的性能,研究团队推出了一套全新的基准测试——Prokaryotic Gener Tasks。这是首个专为原核生物领域设计的基准测试,填补了该领域的空白。
与真核生物领域的基准测试任务(如 NT Task、GUE 和 BEND 等)不同,这些基准测试通常聚焦于人类基因组或缺乏明确的生物学相关性,而 Prokaryotic Gener Tasks 围绕原核生物的实际研究需求展开,提供了一个公平且标准化的比较框架。
Prokaryotic Gener Tasks的设计遵循三大核心原则:任务具有明确的生物学相关性,涵盖广泛的物种以确保泛化能力,并包含从短片段到长片段的多样化序列长度,全面考察模型在不同尺度上的表现。具体而言,基准测试包括多个关键任务:
Gene Fitness Prediction:在不同实验条件下(如pH 值变化、温度波动、化学物质暴露等),预测基因对微生物生存的重要性,揭示环境适应性和代谢通路的关键因素。
Antibiotic Resistance Prediction:基于序列信息直接预测基因是否赋予抗生素抗性,为应对全球抗生素耐药性危机提供了新的工具。
Bacterial Gene Classification:通过纯序列分析,将基因划分为不同的功能类别(如编码序列、伪基因、多种RNA 类型、以及基因间区等),挑战模型在细粒度区分上的能力。
Taxonomic Classification:涵盖从简单到复杂的分类任务,包括基于保守标记基因(如16S rRNA)的分类、混合标记基因的分类,以及直接从随机 DNA 片段中进行物种分类,逐步提升任务难度,全面评估模型的分类能力。
以小胜大:GENERanno性能超越40B同类模型
GENERanno继承并超越了前作 GENERator 的高效设计理念,在 Prokaryotic Gener Tasks 的测试中展现出了超强性能。在与其他同类模型的对比中,GENERanno 几乎在所有任务中胜出。
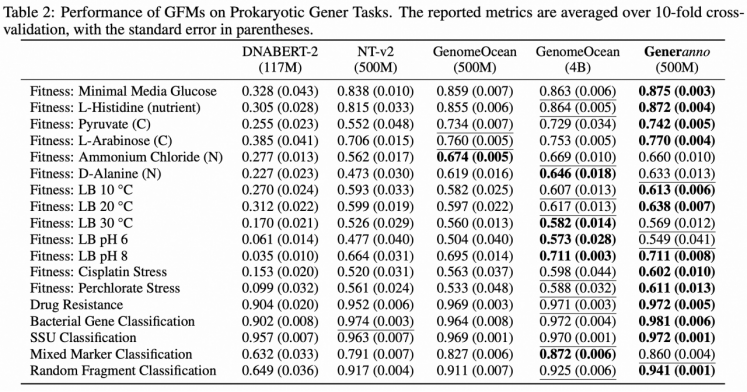
最令人瞩目的是,GENERanno 以仅5亿参数的体量,超越了参数量高达40亿的 GenomeOcean-4B。这种“以小胜大”的表现,直接挑战了 AI 领域的经典假设 Scaling Law(即模型性能随参数量增加而线性提升)。
作者表示,后续将逐步更新GENERanno与METAGENE-7B、Evo-7B、Evo2-7B和Evo2-40B的对比结果。但由于以上模型庞大的算力需求,仍需更多时间完成测试。
开放合作,共创未来
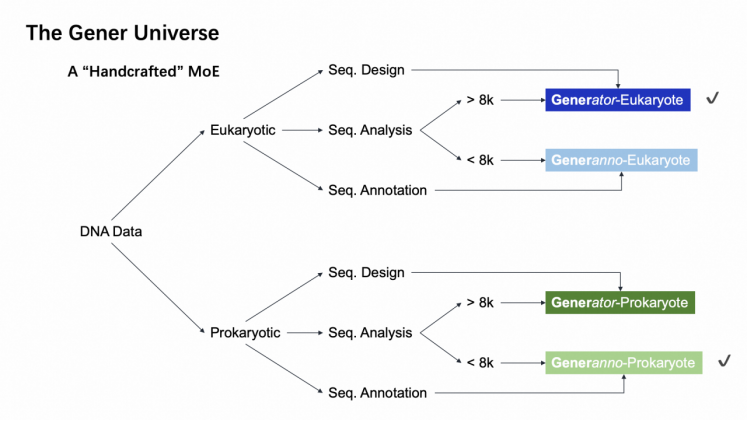
Gener Project 的发起人李秋熠博士表示:“GENERator和GENERanno只是整个Gener Project的半壁江山。我们的长期愿景是通过Gener Project构建一个覆盖真核、原核和病毒基因组的完整生态系统。”
论文链接:
https://www.biorxiv.org/content/10.1101/2025.06.04.656517v1
GitHub:
https://github.com/GenerTeam/GENERanno